
body.orbit:not(.legacy-content) .pageblock .elementor-widget-container:has(> table) {
max-width: 100%;
overflow-x: unset;
border-radius: 0px;
box-shadow: none;
}
body.orbit:not(.legacy-content) .pageblock table tr:first-child td {
background-color: #8017e1 !important;
color: #fff !important;
}
body.orbit:not(.legacy-content) .pageblock table tbody > tr:nth-child(2n+1) > td {
background-color: transparent;
}
body.orbit tbody tr:nth-child(odd) {
background-color: #f7f8fa;
}
body.orbit h2 {
margin-top: 50px;
}
Key Takeaways
- Connect any OpenLineage-compatible orchestrator to the Precisely Data Integrity Suite in minutes — no custom connector required.
- Dataset-level and column-level lineage are both captured automatically based on the event payload.
- Lineage is always complete: when a dataset hasn’t been formally discovered yet, the catalog creates placeholders and automatically enriches them when discovery runs.
Data pipelines have never been more complex. Modern data teams run workloads across a growing mix of orchestration tools — Airflow, Spark, dbt, Dagster — and every new tool traditionally meant a new custom connector just to capture lineage.
The result is fragmented visibility, brittle integrations, and lineage graphs that go stale the moment a tool version change. There’s a better way, and at Precisely, we tackled this challenge directly.
Why Bespoke Lineage Connectors Hold Data Teams Back
Traditional lineage capture requires a dedicated connector for every orchestration tool: one for Dagster, one for Airflow, one for dbt, one for Spark. Each connector evolves on its own schedule, breaks version upgrades, and multiplies maintenance burden with every new tool added.
We solved this by building the Precisely Data Integrity Suite to speak a language that orchestrators already understand: OpenLineage.
What Is OpenLineage and Why Does It Matter for Data Teams?
OpenLineage is an open standard for metadata and lineage collection designed to instrument jobs as they run. When a pipeline job is executed, the orchestrator emits a structured event payload to any HTTP endpoint that supports the protocol.
Because the standard is tool-agnostic and community-maintained, it has achieved broad adoption across the modern data stack. Rather than maintaining proprietary connectors, teams get lineage coverage that grows automatically as the ecosystem evolves.
Every major orchestration tool either ships with built-in support or has a mature community integration:
| Tool | OpenLineage Support |
| Dagster | Built-in via openlineage-dagster |
| Apache Airflow | Built-in via apache-airflow-providers-openlineage |
| dbt | Built-in via dbt-core OpenLineage integration |
| Apache Spark | OpenLineage Spark integration (automatic column lineage) |
| Apache Flink | OpenLineage Flink integration |
| Trino / Starburst | OpenLineage Trino integration |
If your team uses any of these tools, you are one configuration change away from automatic lineage capture.
Connecting Your Orchestrator
How Do You Connect an Orchestrator to the Precisely Data Integrity Suite?
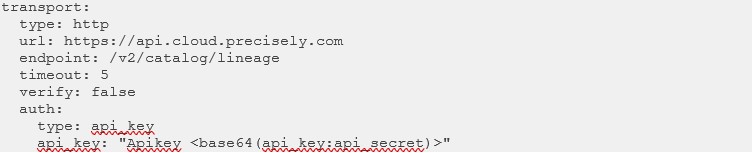
Configure your orchestrator to send events to the Precisely API Gateway:
Endpoint: POST /v2/catalog/lineage
Authentication: API key or bearer token from your workspace credentials
| Region | Value |
| US | https://api.cloud.precisely.com |
| EU | https://api.eu1.cloud.precisely.com |
| GB | https://api.gb1.cloud.precisely.com |
| AU | https://api.au1.cloud.precisely.com |
openlineage.yml example:
No additional setup is needed on the catalog side. Events appear as soon as your next pipeline run completes.
How Events Flow
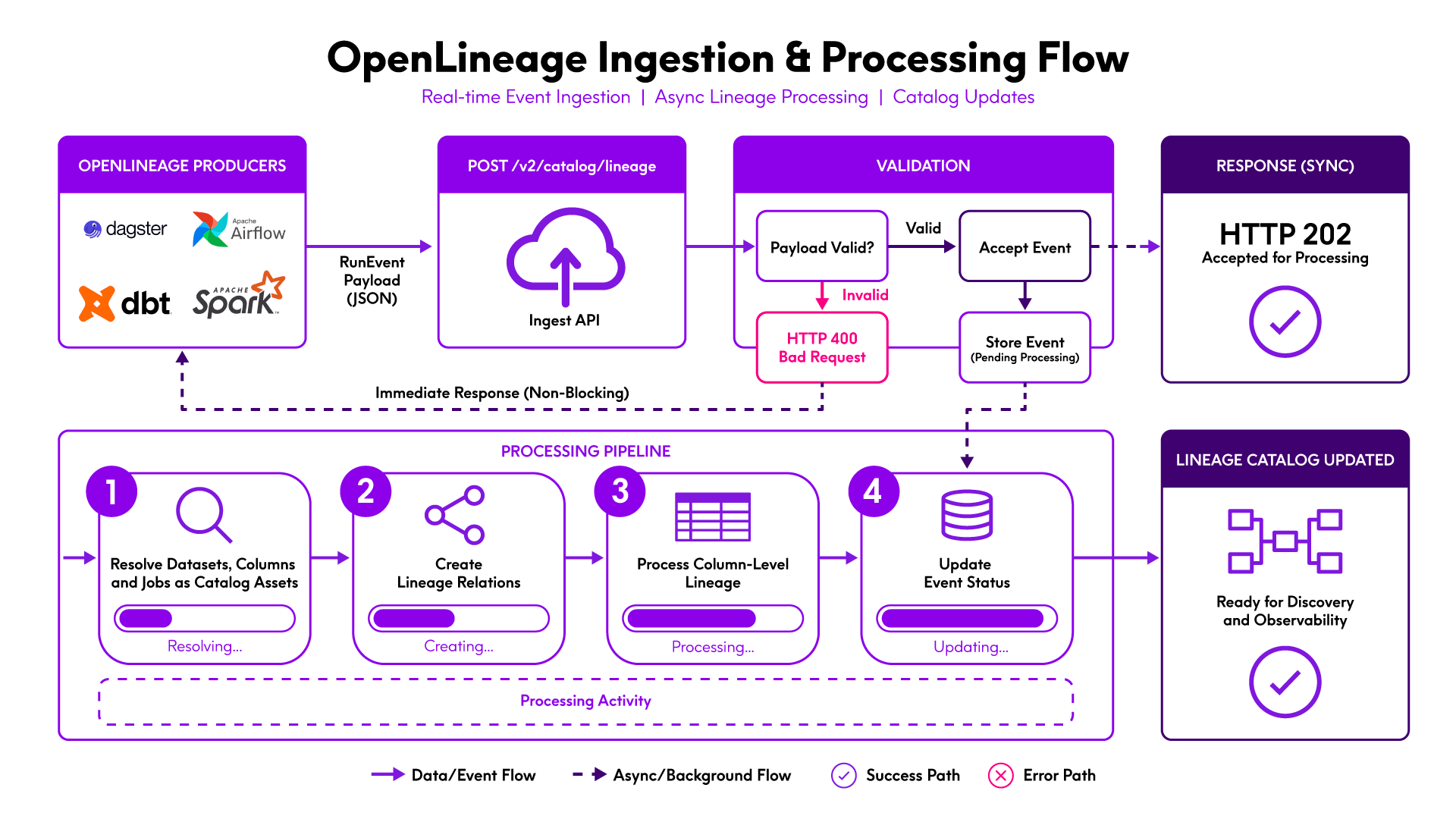
The endpoint acknowledges each event immediately and processes it asynchronously — your orchestrator is never blocked waiting for catalog writes.
What Ends Up in the Catalog
After a pipeline run completes, you get:
- Searchable, browsable Transformation Job assets for every pipeline run
- Lineage edges connecting source and target datasets
- Full column-level lineage with transformation labels
- Placeholder assets that upgrade to fully enriched assets when discovery runs
The Catalog Concept Mapping
| OpenLineage Concept | Catalog Concept |
| Job (namespace + name) | A Transformation Job asset, searchable and browsable |
| Run (unique run ID) | Tracked for audit |
| Dataset (namespace + name) | An existing catalog asset, or a placeholder |
| Input → Output edge | A lineage relation |
| Facets | Asset properties: schema, ownership, data quality, docs |
What Happens When a Dataset Hasn’t Been Discovered Yet?
Pipelines often run before formal data source discovery completes. Rather than dropping lineage edges, the catalog creates placeholder assets — fully navigable catalog entries with provenance metadata from the event. When discovery runs later, the placeholder is enriched with harvested metadata; no lineage edges need rebuilding.
This means lineage is complete from day one — even in environments where data sources are still being cataloged. Teams can trust the graph without waiting for full discovery coverage.
 Pro tip: Dataset/field identifier matching is exact. A case difference, a missing port, or a domain prefix mismatch causes the catalog to create a placeholder instead of linking to an existing asset. Verify your OpenLineage producer’s namespace and name format against your catalog connection settings before enabling production lineage capture.
Pro tip: Dataset/field identifier matching is exact. A case difference, a missing port, or a domain prefix mismatch causes the catalog to create a placeholder instead of linking to an existing asset. Verify your OpenLineage producer’s namespace and name format against your catalog connection settings before enabling production lineage capture.
Column-Level Lineage
How Does Column-Level Lineage Work?
Dataset-level lineage answers which table feeds into which table. Column-level lineage answers which column, transformed how, produces which output column — enabling root-cause analysis and change-impact assessment.
Column-level lineage travels in the column Lineage facet of a COMPLETE event. Tools like Spark and dbt emit this automatically.
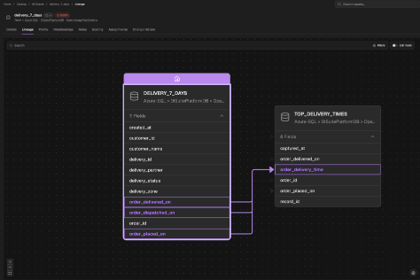
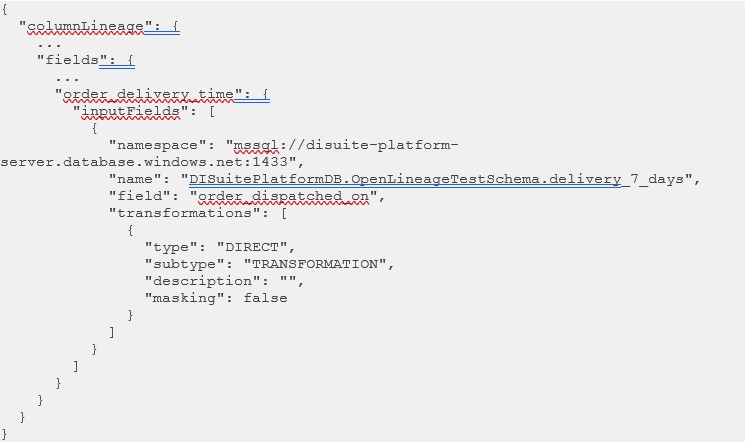
Transformation Job: Full Transformation Context
Each column lineage relation links to a Transformation Job asset that captures:
| Property | What IT Tells You |
| Name | The pipeline that produced this column mapping |
| Type / Subtype | Transformation category (e.g., AGGREGATION / SUM, IDENTITY, TRANSFORMATION) |
| Column Masked | Whether the source value was masked or anonymized |
| Run ID | The specific run that generated this lineage |
| Namespace | The orchestrator environment (e.g., dagster-prod) |
| Event Time | When the pipeline run completed |
| Producer | Which tool emitted the event |
Intelligent Graph: No Duplicate Paths
When column-level lineage is fully resolvable for a source–target pair, the catalog stores column-level relations only. Dataset-level lineage for those pairs is automatically inferred by rollup — so both views appear in the UI without duplicate edges in the graph. For orchestrators that don’t emit columnLineage, the catalog falls back to dataset-level lineage.
Partial Event Resilience
Resolvable column mappings are captured immediately. Unresolvable ones (referencing not-yet-discovered columns) are retried after discovery. An incomplete column mapping never blocks the dataset-level lineage or data quality metadata for the same event.
Reliability You Can Count On
Safe replays: Re-sending the same event has no effect. Lineage relations are not duplicated, Transformation Job assets are not re-created, and metadata is not overwritten.
This matters more than it might seem. In practice, pipeline orchestrators retry on failure, CI/CD systems replay jobs during deployment, and disaster recovery procedures re-run historical events. Without idempotent event handling, each of those scenarios risks corrupting the lineage graph with duplicate edges or stale metadata. The Precisely Data Integrity Suite processes each event exactly once regardless of how many times it is received.
Any tool that emits standard OpenLineage RunEvent payloads to an HTTP endpoint will work.
Summary
| Capability | Detail |
| ✓ Zero-connector integration | Any OpenLineage-compatible tool connects with a URL and a token |
| ✓ Dataset lineage | Automatic lineage relations from every COMPLETE pipeline event |
| ✓ Column lineage | Field-level lineage with transformation type, subtype, description, and masking context |
| ✓ Placeholder assets | Lineage is complete from day one, even before discovery runs |
| ✓ Metadata enrichment | Schema, ownership, data source, and documentation from OpenLineage facets |
| ✓ Safe retries | Duplicate or replayed events never corrupt catalog state |
| ✓ TransformationJob assets | Full provenance trail of what transformed each column and when |
Data pipelines are only as trustworthy as the lineage behind them. By building on an open standard that the modern data stack already speaks, the Precisely Data Integrity Suite makes accurate, consistent, and contextual lineage automatic — so your teams can move fast without second-guessing where their data came from.
_____________________________________________________________________
Frequently Asked Questions
Q. Does OpenLineage work with my existing orchestrator?
A. If your orchestrator is Airflow, Spark, dbt, Dagster, Flink, or Trino/Starburst, built-in or mature community support is available. Configuration is a single YAML change pointing to the Precisely API endpoint. If your tool is not on this list, any tool that emits standard OpenLineage RunEvent payloads over HTTP will also work without modification.
Q. What happens if a dataset hasn’t been discovered yet?
A. The catalog creates a placeholder asset with provenance metadata from the event, keeping lineage edges intact. When discovery runs later, the placeholder is automatically enriched with full metadata. No lineage needs to be rebuilt.
Q. Is dataset-level lineage still available when column-level lineage is captured?
A. Yes. When column-level lineage is resolvable, dataset-level lineage is automatically inferred by rollup so both views are available in the catalog UI. There are no duplicate edges in the graph.
Q. What happens if an event is re-sent or replayed?
A. Nothing changes in the catalog. Events are processed idempotently — re-sending the same event does not create duplicate lineage relations, re-create Transformation Job assets, or overwrite existing metadata.
The post OpenLineage Integration: Bridging Open Standards with the Precisely Data Integrity Suite appeared first on Precisely.


{kind=link}