
{kind=link}
The newly launched Apache Spark troubleshooting agent can get rid of hours of handbook investigation for knowledge engineers and scientists working with Amazon EMR or AWS Glue. As a substitute of navigating a number of consoles, sifting by means of intensive log recordsdata, and manually analyzing efficiency metrics, now you can diagnose Spark failures utilizing easy pure language prompts. The agent robotically analyzes your workloads and delivers actionable suggestions. reworking a time-consuming troubleshooting course of right into a streamlined, environment friendly expertise.
On this submit, we present you ways the Apache Spark troubleshooting agent helps analyze Apache Spark points by offering detailed root causes and actionable suggestions. You’ll discover ways to streamline your troubleshooting workflow by integrating this agent together with your current monitoring options throughout Amazon EMR and AWS Glue.
Apache Spark powers important ETL pipelines, real-time analytics, and machine studying workloads throughout 1000’s of organizations. Nevertheless, constructing and sustaining Spark functions stays an iterative course of the place builders spend important time troubleshooting. Spark software builders encounter operational challenges due to a couple totally different causes:
- Advanced connectivity and configuration choices to quite a lot of assets with Spark – Though this makes Spark a preferred knowledge processing platform, it typically makes it difficult to seek out the basis explanation for inefficiencies or failures when Spark configurations aren’t optimally or accurately configured.
- Spark’s in-memory processing mannequin and distributed partitioning of datasets throughout its employees – Though good for parallelism, this typically makes it tough for customers to establish inefficiencies. This leads to gradual software execution or root explanation for failures attributable to useful resource exhaustion points resembling out of reminiscence and disk exceptions.
- Lazy analysis of Spark transformations – Though lazy analysis optimizes efficiency, it makes it difficult to precisely and shortly establish the appliance code and logic that precipitated the failure from the distributed logs and metrics emitted from totally different executors.
Apache Spark troubleshooting agent structure
This part describes the parts of the troubleshooting agent and the way they connect with your improvement atmosphere. The troubleshooting agent gives a single conversational entry level in your Spark functions throughout Amazon EMR, AWS Glue, and Amazon SageMaker Notebooks. As a substitute of navigating totally different consoles, APIs, and log places for every service, you work together with one Mannequin Context Protocol (MCP) server by means of pure language utilizing any MCP-compatible AI assistant of your alternative, together with customized brokers you develop utilizing frameworks resembling Strands Brokers.
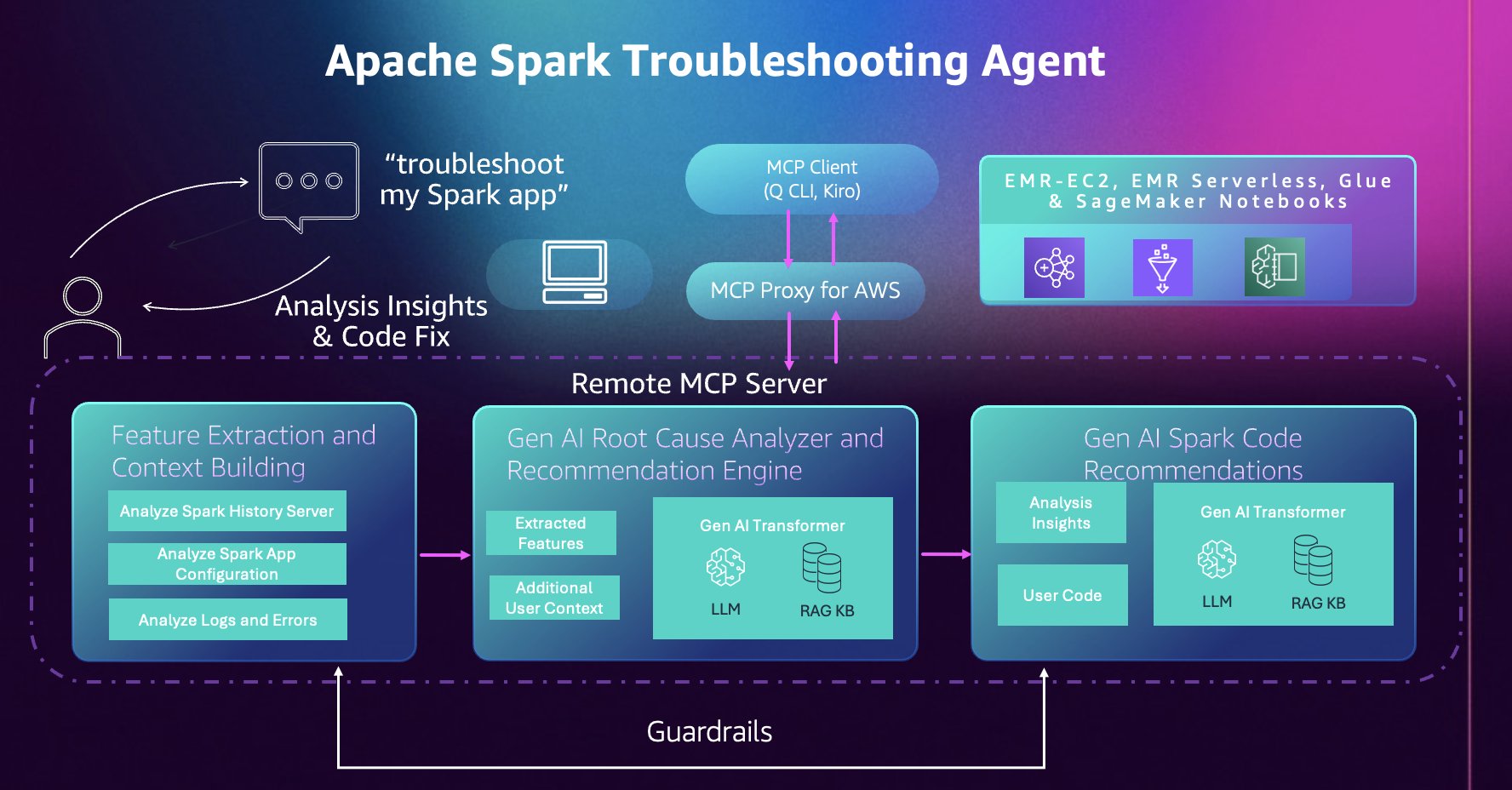
Working as a completely managed cloud-hosted MCP server, the agent removes the necessity to preserve native servers whereas holding your knowledge and code remoted and safe in a single-tenant system design. Operations are read-only and backed by AWS Identification and Entry Administration (IAM) permissions; the agent solely has entry to assets and actions your IAM position grants. Moreover, instrument calls are robotically logged to AWS CloudTrail, offering full auditability and compliance visibility. This mix of managed infrastructure, granular IAM controls, and CloudTrail integration confirms your Spark diagnostic workflows stay safe, compliant, and totally auditable.
The agent builds on years of AWS experience operating hundreds of thousands of Spark functions at scale. It robotically analyzes Spark Historical past Server knowledge, distributed executor logs, configuration patterns, and error stack traces and extracts related options and alerts to floor insights that may in any other case require handbook correlation throughout a number of knowledge sources and deep understanding of Spark and repair internals.
Getting began
Full the next steps to get began with the Apache Spark troubleshooting agent.
Conditions
Confirm you meet or have accomplished the next conditions.
System necessities:
- Python 3.10 or greater
- Set up the uv bundle supervisor. For directions, see putting in uv.
- AWS Command Line Interface (AWS CLI) (model 2.30.0 or later) put in and configured with applicable credentials.
IAM permissions: Your AWS IAM profile wants permissions to invoke the MCP server and entry your Spark workload assets. The AWS CloudFormation template within the setup documentation creates an IAM position with the required permissions. You can even manually add the required IAM permissions.
Arrange utilizing AWS CloudFormation
First, deploy the AWS CloudFormation template offered within the setup documentation. This template robotically creates the IAM roles with the permissions required to invoke the MCP server.
- Deploy the template throughout the similar AWS Area you run your workloads in. For this submit, we’ll use us-east-1.
- From the AWS CloudFormation Outputs tab, copy and execute the atmosphere variable command:
- Configure your AWS CLI profile:
Arrange utilizing Kiro CLI
You need to use Kiro CLI to work together with the Apache Spark troubleshooting agent instantly out of your terminal.
Set up and configuration:
- Set up Kiro CLI.
- Add each MCP servers, utilizing the atmosphere variables from the earlier Arrange utilizing AWS CloudFormation part:
- Confirm your setup by operating the
/instrumentscommand in Kiro CLI to see the out there Apache Spark troubleshooting instruments.
Arrange utilizing Kiro IDE
Kiro IDE gives a visible improvement atmosphere with built-in AI help for interacting with the Apache Spark troubleshooting agent.
Set up and configuration:
- Set up Kiro IDE.
- MCP configuration is shared throughout Kiro CLI and Kiro IDE. Open the command palette utilizing
Ctrl + Shift + P(Home windows / Linux) orCmd + Shift + P(macOS) and Seek forKiro: Open MCP Config - Confirm the contents of your
mcp.jsonmatch the Arrange utilizing Kiro CLI part.
Utilizing the troubleshooting agent
Subsequent, we offer 3 reference architectures for options to make use of the troubleshooting agent in your current workflows with ease. We additionally present the reference code and AWS CloudFormation templates for these architectures within the Amazon EMR Utilities GitHub repository.
Resolution 1 – Conversational troubleshooting: Troubleshooting failed Apache Spark functions with Kiro CLI
When Spark functions fail throughout your knowledge platform, your debugging method would usually contain navigating totally different consoles for Amazon EMR, Amazon EC2, Amazon EMR Serverless, and AWS Glue, manually reviewing Spark Historical past Server logs, checking error stack traces, analyzing useful resource utilization patterns, then correlating this data to seek out the basis trigger and repair. The Apache Spark troubleshooting agent automates this whole workflow by means of pure language, offering a unified troubleshooting expertise throughout the three platforms. Merely describe your failed functions, for instance:
The agent robotically extracts Spark occasion logs and metrics, analyzes the error patterns, and gives a transparent root trigger clarification together with suggestions, all by means of the identical conversational interface. The next video demonstrates the whole troubleshooting workflow throughout Amazon EMR-EC2, Amazon EMR Serverless, and AWS Glue utilizing Kiro CLI:
Resolution 2 – Agent-driven notifications: Combine the Apache Spark troubleshooting agent right into a monitoring workflow
Along with troubleshooting from the command line, the troubleshooting agent can plug into your monitoring infrastructure to supply improved failure notifications.
Manufacturing knowledge pipelines require rapid visibility when failures happen. Conventional monitoring programs can provide you with a warning when a Spark job fails, however diagnosing the basis trigger nonetheless requires handbook investigation and an evaluation of what went flawed earlier than remediation can start.
With the Apache Spark troubleshooting agent, you’ll be able to combine it into your current monitoring workflows to obtain root causes and proposals as quickly as you obtain a failure notification. Right here, we show two integration patterns that end in automated root trigger evaluation inside your current workflows.
Apache Airflow Integration
This primary integration sample makes use of Apache Airflow callbacks to robotically set off troubleshooting when Spark job operators fail.
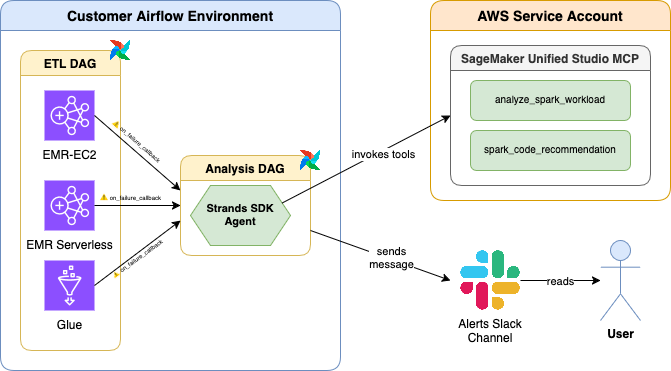
When any Amazon EMR, Amazon EC2, Amazon EMR Serverless, or AWS Glue job operator fails in an Apache Airflow DAG,
- A callback invokes the Spark troubleshooting agent inside a separate DAG.
- The Spark troubleshooting agent analyzes the problem, establishes the basis trigger, and identifies code repair suggestions.
- The Spark troubleshooting agent sends a complete diagnostic report back to a configured Slack channel.
The answer is out there within the Amazon EMR Utilities GitHub repository (documentation) for rapid integration into your current Apache Airflow deployments with a 1-line change to your Airflow DAGs. The next video demonstrates this integration:
Amazon EventBridge integration
For event-driven architectures, this second sample makes use of Amazon EventBridge to robotically invoke the troubleshooting agent when Spark jobs fail throughout your AWS atmosphere.
This integration makes use of an AWS Lambda perform that interacts with the Apache Spark troubleshooting agent by means of the Strands MCP Shopper.
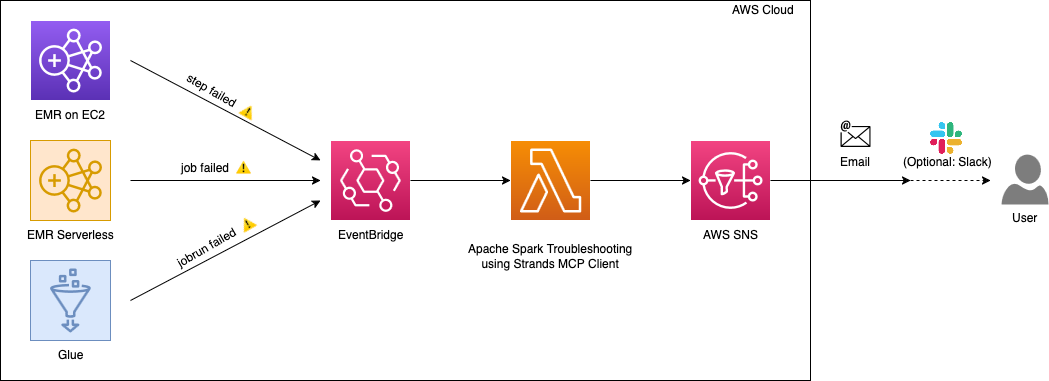
When Amazon EventBridge detects failures from Amazon EMR-EC2 steps, Amazon EMR Serverless job runs, or AWS Glue job runs, it triggers the AWS Lambda perform which:
- Makes use of the Apache Spark troubleshooting agent to investigate the failure
- Identifies the basis trigger and generates code repair suggestions
- Constructs a complete evaluation abstract
- Sends the abstract to Amazon SNS
- Delivers the evaluation to your configured locations (electronic mail, Slack, or different SNS subscribers)
This serverless method gives centralized failure evaluation throughout all of your Spark platforms with out requiring modifications to particular person pipelines. The next video demonstrates this integration:
A reference implementation of this resolution is out there within the Amazon EMR Utilities GitHub repository (documentation).
Resolution 3 – Clever Dashboards: Use the Apache Spark troubleshooting agent with Kiro IDE to visualise account stage software failures: what failed, why failed and repair
Understanding the well being of your Spark workloads throughout a number of platforms requires consolidating knowledge from Amazon EMR (each EC2 and Serverless) and AWS Glue. Groups usually construct customized monitoring options by writing scripts to question a number of APIs, combination metrics, and generate studies which may be time consuming and require energetic upkeep.
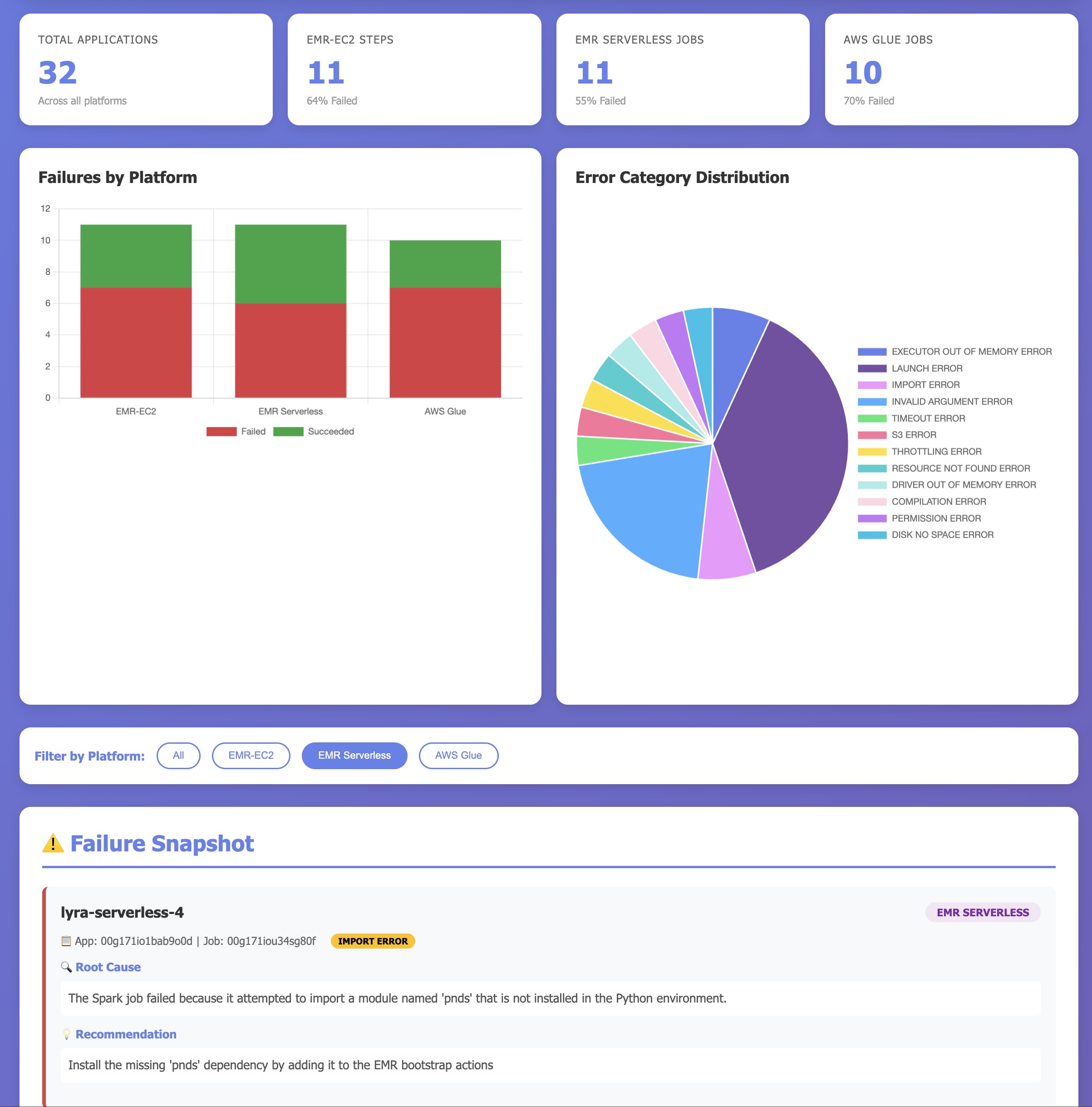
With Kiro IDE and the Apache Spark troubleshooting agent, you’ll be able to construct complete monitoring dashboards conversationally. As a substitute of writing customized code to combination workload metrics, you’ll be able to describe what you need to monitor, and the agent generates an entire dashboard exhibiting total efficiency metrics, error class distributions for failures, success charges throughout platforms, and significant failures requiring rapid consideration. Not like conventional dashboards that solely present conventional KPIs and metrics on what software failed, this dashboard makes use of the Spark troubleshooting agent to supply insights to customers on why the functions failed, and how they are often fastened. The next video demonstrates constructing a multi-platform monitoring dashboard utilizing Kiro IDE:
The immediate used throughout the demo:
Clear up
To keep away from incurring future AWS prices, delete the assets you created throughout this walkthrough:
- Delete the AWS CloudFormation stack.
- In case you created an Amazon EventBridge rule for integration, delete these assets.
Conclusion
On this submit, we demonstrated how the Apache Spark troubleshooting agent transforms hours of handbook investigation into pure language conversations, considerably lowering troubleshooting time from hours to minutes and making Spark experience accessible to all. By integrating pure language diagnostics into your current improvement instruments—whether or not Kiro CLI, Kiro IDE, or different MCP-compatible AI assistants—your groups can give attention to constructing progressive functions as a substitute of debugging failures.
Particular thanks
A particular due to everybody who contributed from engineering and science to the launch of the Spark troubleshooting agent and the distant MCP service: Tony Rusignuolo, Anshi Shrivastava, Martin Ma, Hirva Patel, Pranjal Srivastava, Weijing Cai, Rupak Ravi, Bo Li, Vaibhav Naik, XiaoRun Yu, Tina Shao, Pramod Chunduri, Ray Liu, Yueying Cui, Savio Dsouza, Kinshuk Pahare, Tim Kraska, Santosh Chandrachood, Paul Meighan and Rick Sears.
A particular due to all of our companions who contributed to the launch of the Spark troubleshooting agent and the distant MCP service: Karthik Prabhakar, Suthan Phillips, Basheer Sheriff, Kamen Sharlandjiev, Archana Inapudi, Vara Bonthu, McCall Peltier, Lydia Kautsky, Larry Weber, Jason Berkovitz, Jordan Vaughn, Amar Wakharkar, Subramanya Vajiraya, Boyko Radulov and Ishan Gaur.
In regards to the authors