
{kind=link}
I like this scene from Jurassic Park
Individuals at all times bear in mind this scene for the might/ought to line however I believe that basically minimizes Malcolms holistically wonderful speech. Particularly, this scene is an incredible analogy for Machine Studying/AI know-how proper now. I’m not going to dive an excessive amount of into the ethics piece right here as Jamie Indigo has a couple of superb items on that already, and established lecturers and authors like Dr. Safiya Noble and Ruha Benjamin greatest take care of the ethics teardown of search know-how.
I’m right here to speak about how we right here at LSG earn our data and a few of what that data is.
“I’ll inform you the issue with the scientific energy that you’re utilizing right here; it didn’t require any self-discipline to achieve it. You learn what others had performed and also you took the subsequent step.”
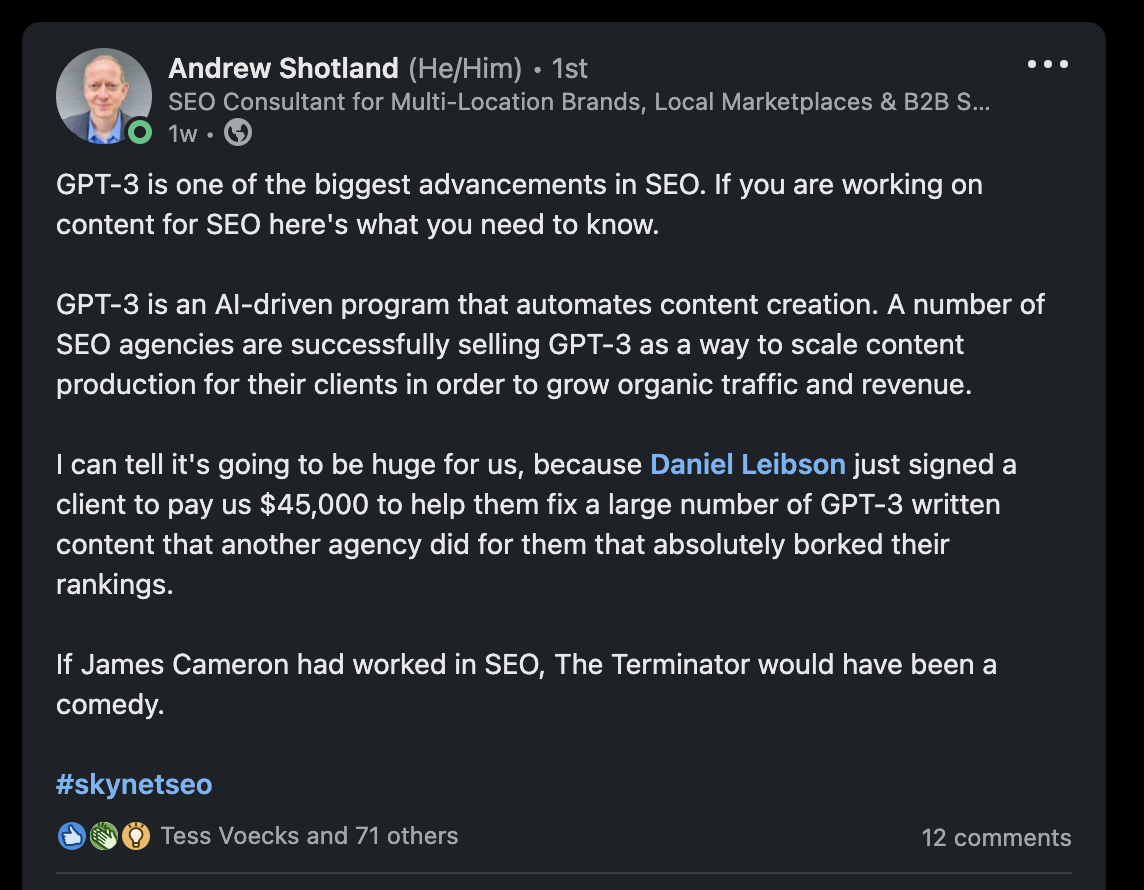
I really feel like this situation described within the screenshot (poorly written GPT-3 content material that wants human intervention to repair) is a superb instance of the mindset described within the Jurassic Park quote. This mindset is rampant within the search engine marketing trade in the mean time. The proliferation of programmatic sheets and collab notebooks and code libraries that folks can run with out understanding them ought to want no additional clarification to ascertain. Only a primary take a look at the SERPs will present a myriad of NLP and forecasting instruments which might be launched whereas being straightforward to entry and use with none understanding of the underlying maths and strategies. $SEMR simply deployed their very own key phrase intent software, completely flattening a posh course of with out their end-users having any understanding of what’s going on (however extra on this one other day). These maths and strategies are completely vital to have the ability to responsibly deploy these applied sciences. Let’s use NLP as a deep dive as that is an space the place I believe we now have earned our data.
“You didn’t earn the data for yourselves so that you don’t take any accountability for it.”
The accountability right here is just not moral, it’s final result oriented. In case you are utilizing ML/NLP how are you going to be certain it’s getting used for consumer success? There may be an outdated information mungling adage “Rubbish In, Rubbish Out” that’s about illustrating how necessary preliminary information is:

https://xkcd.com/1838/
The stirring right here simply actually makes this comedian. It’s what lots of people do once they don’t perceive the maths and strategies of their machine studying and name it “becoming the info.”
This can be extrapolated from information science to basic logic e.g. the premise of an argument. As an illustration, if you’re attempting to make use of a forecasting mannequin to foretell a site visitors enhance you would possibly assume that “The site visitors went up, so our predictions are possible true” however you actually can’t perceive that with out understanding precisely what the mannequin is doing. In the event you don’t know what the mannequin is doing you possibly can’t falsify it or have interaction in different strategies of empirical proof/disproof.
HUH?
Precisely, so let’s use an instance. Lately Rachel Anderson talked about how we went about attempting to know the content material on numerous pages, at scale utilizing varied clustering algorithms. The preliminary objective of utilizing the clustering algorithms was to scrape content material off a web page, collect all this related content material over your complete web page kind on a website, after which do it for opponents. Then we might cluster the content material and see the way it grouped it so as to higher perceive the necessary issues individuals had been speaking about on the web page. Now, this didn’t work out in any respect.
We went by way of varied strategies of clustering to see if we might get the output we had been in search of. In fact, we bought them to execute, however they didn’t work. We tried DBSCAN, NMF-LDA, Gaussian Combination Modelling, and KMeans clustering. These items all do functionally the identical factor, cluster content material. However the precise methodology of clustering is totally different.
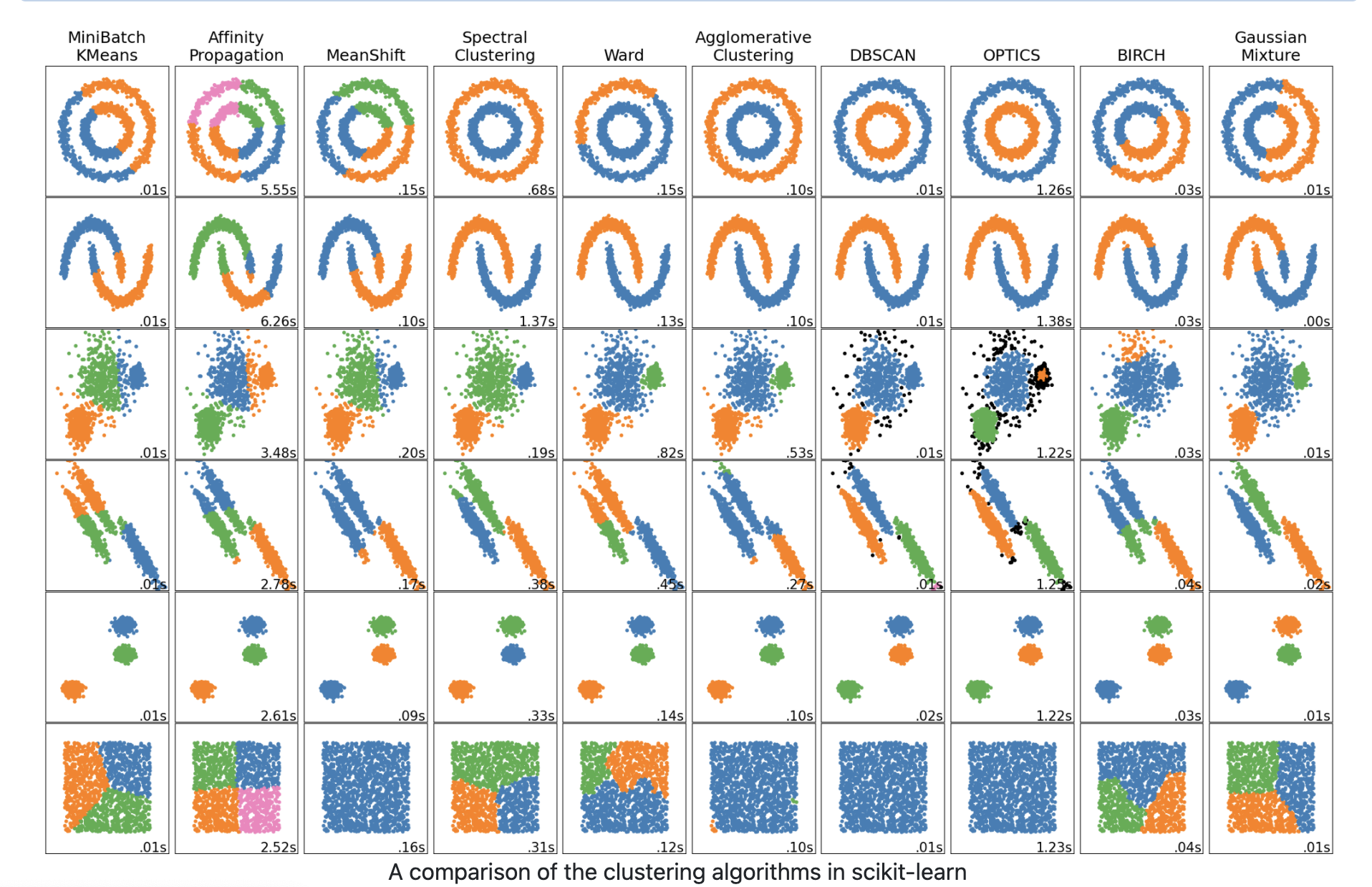
https://scikit-learn.org/steady/modules/clustering.html
We used the scikit-learn library for all our clustering experiments and you’ll see right here of their data base how totally different clustering algorithms group the identical content material in several methods. Actually they even break down some potential usecases and scalability;

https://scikit-learn.org/steady/modules/clustering.html
Not all of those methods are more likely to result in optimistic search outcomes, which is what it means to work whenever you do search engine marketing. It seems we weren’t truly in a position to make use of these clustering strategies to get what we wished. We determined to maneuver to BERT to unravel a few of these issues and roughly that is what led to Jess Peck becoming a member of the workforce to personal our ML stack in order that they might be developed in parallel with our different engineering initiatives.
However I digress. We constructed all these clustering strategies, we knew what labored and didn’t work with them, was all of it a waste?
Hell no, Dan!
One of many issues I seen in my testing was that KMeans clustering works extremely properly with a lot of concise chunks of information. Effectively, in search engine marketing we work with key phrases, that are a lot of concise chunks of information. So after some experiments with making use of the clustering methodology to key phrase information units, we realized we had been on to one thing. I received’t bore you on how we fully automated the KMeans clustering course of we now use however understanding the methods varied clustering maths and processes labored to allow us to use earned data to show a failure into success. The primary success is permitting the fast ad-hoc clustering/classification of key phrases. It takes about 1hr to cluster a number of hundred thousand key phrases, and smaller quantities than a whole lot of hundreds are lightning-fast.
Neither of those firms are purchasers, simply used them to check however after all if both of you needs to see the info simply HMU 🙂
We just lately redeveloped our personal dashboarding system utilizing GDS in order that it may be based mostly round our extra sophisticated supervised key phrase classification OR utilizing KMeans clustering so as to develop key phrase classes. This offers us the power to categorize consumer’s key phrases even on a smaller finances. Right here is Heckler and I testing out utilizing our slackbot Jarvis to KMeans cluster consumer information in BigQuery after which dump the output in a client-specific desk.

This offers us an extra product that we are able to promote, and provide extra subtle strategies of segmentation to companies that wouldn’t usually see the worth in costly huge information initiatives. That is solely doable by way of incomes the data, by way of understanding the ins and outs of particular strategies and processes to have the ability to use them in the very best approach. That is why we now have spent the final month or so with BERT, and are going to spend much more extra time with it. Individuals could deploy issues that hit BERT fashions, however for us, it’s a few particular perform of the maths and processes round BERT that make it notably interesting.
“How is that this one other accountability of SEOs”
Thanks, random web stranger, it’s not. The issue is with any of this ever being an search engine marketing’s accountability within the first place. Somebody who writes code and builds instruments to unravel issues known as an engineer, somebody who ranks web sites is an search engine marketing. The Discourse usually forgets this key factor. This distinction is a core organizing precept that I baked into the cake right here at LSG and is harking back to an ongoing debate I used to have with Hamlet Batista. It goes a little bit one thing like this;
“Ought to we be empowering SEOs to unravel these issues with python and code and so forth? Is that this an excellent use of their time, versus engineers who can do it faster/higher/cheaper?”
I believe empowering SEOs is nice! I don’t suppose giving SEOs a myriad of duties which might be greatest dealt with by a number of totally different SMEs may be very empowering although. That is why we now have a TechOps workforce that’s 4 engineers sturdy in a 25 individual firm. I simply basically don’t imagine it’s an search engine marketing’s accountability to learn to code, to determine what clustering strategies are higher and why, or to learn to deploy at scale and make it accessible. When it’s then they get shit performed (yay) standing on the shoulders of giants and utilizing unearned data they don’t perceive (boo). The frenzy to get issues performed the quickest whereas leveraging others earned data (standing on the shoulders of giants) leaves individuals behind. And SEOs take no accountability for that both.
Leaving your Workforce Behind
A factor that usually will get misplaced on this dialogue is that when info will get siloed particularly people or groups then the good thing about mentioned data isn’t usually accessible.
Not going to name anybody out right here, however earlier than I constructed out our TechOps construction I did a bunch of “get out of the constructing” analysis in speaking to others individuals at different orgs to see what did or didn’t work about their organizing ideas. Principally what I heard match into both two buckets:
- Particular SEOs learn to develop superior cross-disciplinary expertise (coding, information evaluation and so forth) and the data and utility of mentioned data aren’t felt by most SEOs and purchasers.
- The data will get siloed off in a workforce e.g. Analytics or Dev/ENG workforce after which will get bought as an add on which suggests mentioned data and utility aren’t felt by most SEOs and purchasers.
That’s it, that’s how we get stuff performed in our self-discipline. I believed this kinda sucked. With out getting an excessive amount of into it right here, we now have a construction that’s just like a DevOps mannequin. We have now a workforce that builds instruments and processes for the SMEs that execute on search engine marketing, Internet Intelligence, Content material, and Hyperlinks to leverage. The objective is particularly to make the data and utility accessible to everybody, and all our purchasers. That is why I discussed how KMeans and owned data helped us proceed to work in direction of this objective.


I’m not going to get into Jarvis stats (clearly we measure utilization) however suffice to say it’s a hard-working bot. That’s as a result of a workforce is simply as sturdy because the weakest hyperlink, so slightly than burden SEOs with extra accountability, orgs ought to concentrate on incomes data in a central place that may greatest drive optimistic outcomes for everybody.